当ブログのコンテンツ・情報について、できる限り正確な情報を提供するように努めておりますが、正確性や安全性を保証するものではありません。
当サイトに掲載された内容によって生じた損害等の一切の責任を負いかねますので、予めご了承ください。
PythonのMeCabで形態素解析をする方法

この記事ではWindows11環境のPythonでMeCabを利用した形態素解析をする方法を解説します。
目次
形態素解析とは?
形態素解析とは、日本語の文章を単語単位に分割し、それぞれの単語に品詞や活用形などの情報を付与する処理です。
英語のような言語は単語と単語の区切りにスペースを用いるので、単語の分割は容易です。一方で、日本語はスペースで単語が区切られないため、自然言語処理を行う際に形態素解析が重要な前処理として位置付けられます。
この記事で使用するPythonライブラリ・外部ツール
この記事では以下のPythonライブラリ・外部ツールを使用します。
| ライブラリ | 用途 | ライセンス |
|---|---|---|
| MeCab(外部ツール) | 日本語専用形態素解析ツール | 修正BSD, LGPL, GPL |
| mecab-python3 | PythonでMeCabを利用するためのライブラリ | 修正BSD, LGPL, GPL |
MeCab
MeCab(メカブ)は、自然言語処理における形態素解析を行うための日本語形態素解析エンジンです。
- 高速性
- MeCabは非常に高速で、大量のデータを処理する場合にも有効です。
- オープンソース
- MeCabはオープンソースソフトウェアであり、誰でも自由に利用できます。
- カスタマイズ可能な辞書
- デフォルトのIPA辞書以外にも、NEologd(新語辞書)やUnidicなどの辞書を利用でき、特定の用途やドメインに合わせて辞書を変更できます。
- さまざまな出力形式
- MeCabは形態素解析結果を多様な形式で出力できます(例: Chasen形式, 簡易形式など)。
- プログラム連携
- Python、C++、Java、Rubyなど、多くのプログラミング言語から利用可能です。
mecab-python3
Pythonで日本語形態素解析エンジン「MeCab」を利用するための公式バインディングライブラリです。このライブラリを使用することで、Pythonから直接MeCabを操作して形態素解析を行うことができます。
- Pythonとの統合
- MeCabをPythonコードで簡単に扱うことができ、形態素解析の結果を文字列やデータ構造として操作可能です。
- 軽量・高速
- MeCab自体が高速であるため、大量のデータをPythonで効率的に処理できます。
- カスタマイズ可能
- MeCabの辞書(IPA辞書、Unidic、NEologdなど)や解析オプションを簡単に指定可能。
- クロスプラットフォーム
- Linux、macOS、Windowsで動作します。ただし、WindowsではMeCab本体のインストールが必要です。
環境構築
STEP
仮想環境の構築
MeCabを使用するだけであれば、仮想環境の構築は必須ではありません。
CaboChaを使用した係り受け解析も行いたい場合は32bit版Pythonが必要です。通常は64bit版Pythonをインストールしていると思うので、32bit版を別途インストールし仮想環境を構築する必要があります。
あわせて読みたい

Windows11でPython仮想環境を構築する方法
Pythonの仮想環境を使うことで、異なるプロジェクト間でのライブラリの衝突を防ぎ、開発作業がスムーズに進められます。この記事では、Windows11でPythonの仮想環境を構...
STEP
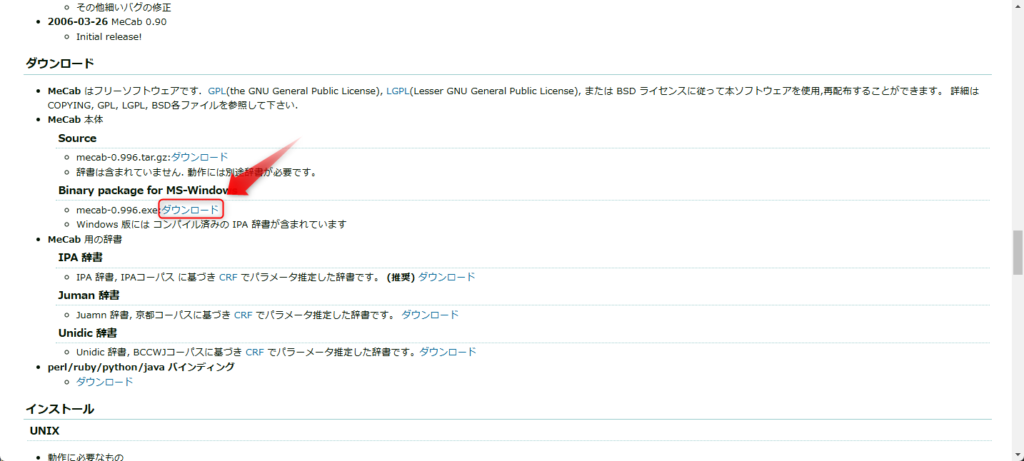
MeCabのインストール
実行ファイル(mecab-0.996.exe)を実行します。インストーラーの指示通りにセットアップを完了します。
注意点は、Pythonで使用するためには文字コードの選択で「UTF-8」を選択します。
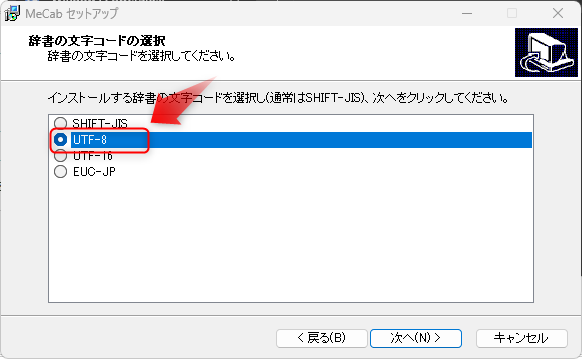
なお、「UTF-8」を選択するとPythonからMeCabを正常に使用できるようになりますが、コマンドライン(PowerShellやコマンドプロンプト)から直接Mecabを使用すると文字化けしてしまいます。
Python及びコマンドラインの両方で正常に使用できるようにするためには、「UTF-8」と「SHIFT-JIS」の両方をインストールする必要があります。
その方法については下記サイトを参考にしてください。本記事で「UTF-8」のみをインストールします。
Qiita

【Windows10,11】Python 3.10 (32bit) にMeCab, CaboChaを導入してみた - Qiita
はじめに 筆者がWindows PCにCaboChaを入れる際に情報が古くて手こずったので、備忘録として導入方法を記しておきます。 確認済動作環境 Windows 10, 11 (64bit) Python 3....
STEP
必要なライブラリのインストール
以下のコマンドをPowerShellで実行してください。
pip install mecab-python3形態素解析の実施例
基本的な形態素解析
以下は、MeCabを使った形態素解析の基本的な例です。
import MeCab
# MeCabインスタンスを作成
mecab = MeCab.Tagger("-Ochasen") # 出力フォーマットを指定
text = "形態素解析を試してみます。"
# 形態素解析を実行
result = mecab.parse(text)
print(result)出力例:
形態素 ケイタイソ 形態素 名詞-一般
解析 カイセキ 解析 名詞-サ変接続
を ヲ を 助詞-格助詞-一般
試し タメシ 試す 動詞-自立 五段・サ行 連用形
て テ て 助詞-接続助詞
み ミ みる 動詞-非自立 一段 連用形
ます マス ます 助動詞 特殊・マス 基本形
。 。 。 記号-句点
EOS単語のリストをカンマ区切りで取得
以下は、入力テキストから単語のリストを抽出し、カンマ区切りの文字列に変換する方法です。
import MeCab
def get_words_as_csv(text):
# MeCabインスタンスを作成
mecab = MeCab.Tagger("-Owakati") # 分かち書きモードを指定
# 分かち書きの結果を取得
wakati_result = mecab.parse(text).strip() # 改行を削除
# 単語をカンマ区切りに変換
csv_result = ",".join(wakati_result.split())
return csv_result
# テキスト入力
text = "形態素解析を試してみます。"
csv_output = get_words_as_csv(text)
print(csv_output)出力例:
形態素,解析,を,試し,て,み,ます,。特定の品詞のみを抽出してカンマ区切りで取得
特定の品詞(例えば名詞と動詞)を抽出してカンマ区切りで取得するには、形態素解析結果をフィルタリングします。
import MeCab
def extract_specific_pos_as_csv(text, target_pos=("名詞", "動詞")):
# MeCabインスタンスを作成
mecab = MeCab.Tagger()
# 形態素解析の結果をノード単位で取得
node = mecab.parseToNode(text)
words = []
while node:
# 品詞情報を取得 (feature をカンマで分割して最初の要素が品詞)
features = node.feature.split(",")
if features[0] in target_pos: # 品詞が指定したものに一致する場合
words.append(node.surface) # 表層形をリストに追加
node = node.next
# カンマ区切りに変換して返す
return ",".join(words)
# テキスト入力
text = "形態素解析を試してみます。名詞と動詞だけを抽出します。"
csv_output = extract_specific_pos_as_csv(text)
print(csv_output)出力例:
形態素,解析,試し,み,名詞,動詞,抽出,しMeCabと辞書
MeCabで使用できる主な辞書を紹介します。
| 辞書 | 特徴 |
|---|---|
| IPA辞書 | 標準的な日本語辞書で汎用性が高い 名詞、動詞、形容詞、助詞などの標準的な品詞を網羅 収録語彙は豊富だが、新語や専門用語には弱い |
| Juman辞書 | 京都大学が開発した形態素解析ツール「Juman」に最適化された辞書 日本語の文脈依存解析に優れる(特に長い文や複雑な文の解析) 豊富な辞書語彙を持つが、デフォルトで専門用語には弱い 主に学術分野での利用が多い |
| Unidic | 詳細な文法情報(例: 文節、句構造、アクセント情報など)を提供 形態素の詳細な情報(活用形や接続条件など)を含む 品詞の分類が非常に細かい |
| NEologd | 新語・流行語を多く収録(例: SNS用語、時事用語) 独自の単語頻度データを元にしたコスト設計により解析精度が向上 辞書サイズが大きく、インストールや更新に時間がかかる |
IPA辞書
IPA辞書(IPA辞書モデル、IPA辞書形式)は、MeCabや他の形態素解析エンジンで使用される日本語形態素解析用の辞書で、日本の国立研究開発法人情報通信研究機構(NICT)が提供しています。「IPA辞書」という名称は、「情報通信研究機構 日本語基盤技術(IPA)」プロジェクトに由来します。
| IPA辞書の利点 | IPA辞書の欠点 |
|---|---|
| 一般的な日本語文章を解析するために十分な語彙を提供 名詞、動詞、助詞、接続詞など、日本語文法に基づいた正確な品詞情報が得られる ユーザー定義辞書を追加して、専門用語や新語をカバー可能 | 流行語や専門用語(特に技術分野の単語)には対応しきれない場合がある 辞書ファイルが大きいため、メモリやディスク容量に影響を与える可能性がある。 日本語の文法特性上、複数の解析結果が存在する場合があり、必ずしも期待通りに解析されないことがある。 |
- 汎用性
- 日本語の一般的な文章を解析するために広く使用されています。
- 標準的な品詞分類と単語の活用情報が含まれており、一般的なテキスト解析には十分な性能を発揮します。
- 収録語彙
- 一般的な日本語単語、助詞、助動詞、接続詞、記号などが収録されています。
- 日常会話や標準的な文書で使用される単語を広くカバーしています。
- 品詞と形態素情報
- 単語ごとに以下のような情報を提供します。
- 品詞(例: 名詞、動詞、形容詞)
- 活用形(例: 五段活用、形容詞活用)
- 基本形(原形、辞書形)
- 読み仮名(かな表記)
- 発音(発音表記)
- 単語ごとに以下のような情報を提供します。
- 形式
- 辞書はCSV形式で提供され、MeCabが利用可能な形式に変換して使用します。
- 各行が1つの形態素(単語や記号など)に対応しています。
Juman辞書
Juman辞書は、形態素解析エンジン「Juman」に対応した日本語形態素解析用の辞書です。Jumanは、京都大学情報学研究科で開発された高精度な形態素解析ツールで、Juman辞書はその解析精度を支える重要な要素です。この辞書は、日本語文法に忠実で詳細な解析を提供することを目的としています。
| Juman辞書の利点 | Juman辞書の欠点 |
|---|---|
| 日本語文法に忠実で、詳細な品詞情報を提供 専門分野や研究用途にも適した高精度な解析が可能 文脈情報を考慮した正確な形態素解析を実現 | 処理速度が比較的遅い場合がある 辞書ファイルが大きく、システムリソースを多く消費する 新語や流行語への対応は限定的 |
- 汎用性
- 日本語の厳密な文法規則に基づいて解析を行います。
- 研究用途や特殊なテキスト解析にも適しています。
- 収録語彙
- 一般的な単語に加えて、文法的に重要な形態素や接続語も詳細に収録。
- 形容詞や動詞の活用形が明確に定義されています。
- 品詞と形態素情報
- 単語ごとに以下の情報を提供します。
- 品詞(例: 名詞、動詞、形容詞、助詞)
- 活用形(例: 未然形、連用形、終止形など)
- 基本形(原形、辞書形)
- 文脈的な接続情報
- 単語ごとに以下の情報を提供します。
- 形式
- Juman専用の辞書形式で提供され、解析エンジンに組み込んで利用します。
- 各形態素に詳細な文法情報を付与しています。
Unidic
Unidicは、日本語の形態素解析や自然言語処理に使用される高精度な辞書で、国立国語研究所(NINJAL)によって開発されています。Unidicは、日本語の音声認識やテキスト解析に特化して設計されており、詳細な品詞分類と活用情報を提供します。また、語彙情報が豊富で、現代日本語の多様な文法構造をカバーしています。
| Unidicの利点 | Unidicの欠点 |
|---|---|
| 豊富な語彙情報と詳細な文法データを提供 文法構造や音韻情報など、解析に必要な付加情報が充実 現代日本語の多様な文法現象を高精度で解析可能 | 辞書サイズが大きく、メモリ消費が高い 解析速度が他の辞書と比較して遅い場合がある 新語や流行語には対応が不十分な場合がある |
- 汎用性
- 日本語の多様な文法構造や音声認識用途に対応可能。
- 自然言語処理や研究用途にも適しています。
- 収録語彙
- 一般的な日本語単語に加え、方言や専門用語、古語なども収録。
- 語彙の音韻情報やアクセント情報を含んでいます。
- 品詞と形態素情報
- 単語ごとに以下の情報を提供します。
- 品詞(例: 名詞、動詞、形容詞、助詞、助動詞)
- 活用形(例: 未然形、連用形、終止形、連体形など)
- 基本形(辞書形)
- 発音・アクセント情報
- 語彙の出現頻度や統計情報
- 単語ごとに以下の情報を提供します。
- 形式
- 辞書はUnidic形式で提供され、MeCabや他の形態素解析エンジンと連携して使用可能。
- 各形態素に対して詳細な文法的・統計的情報が付加されています。
NEologd
NEologdは、日本語形態素解析用の拡張辞書で、新語や流行語、固有名詞(企業名、商品名、人名など)を多く収録しています。NEologdは、標準的なMeCab辞書(IPA辞書)をベースに、新たな語彙や更新頻度の高い単語を追加して拡張されています。この辞書は、特にSNSやニュース記事のような新語が頻出するデータの解析において高い効果を発揮します。
| NEologdの利点 | NEologdの欠点 |
|---|---|
| 新語や流行語、固有名詞の解析に強い SNSやニュースなど、頻繁に更新されるデータに対応 IPA辞書との互換性があり、簡単に導入可能 | 辞書サイズが大きく、メモリ消費が高い 作成や更新に時間がかかる 一般的なテキスト解析には過剰な場合がある |
- 汎用性
- 新語や固有名詞を多く含むため、SNSやニュース、ブログ解析に特化しています。
- 標準的な形態素解析エンジンで使用可能で、追加のカスタマイズも容易です。
- 収録語彙
- 企業名、商品名、地名、イベント名、人名、流行語、新語などを豊富に収録。
- 日本語の最新トレンドに基づいて定期的に更新されています。
- 品詞と形態素情報
- 単語ごとに以下の情報を提供します。
- 品詞(例: 名詞、動詞、形容詞、固有名詞)
- 活用形(例: 未然形、連用形など)
- 基本形(辞書形)
- 読み仮名と発音
- 追加された新語・固有名詞の語彙情報
- 単語ごとに以下の情報を提供します。
- 形式
- MeCabのIPA辞書形式を拡張しており、容易に導入できます。
- 辞書はCSV形式で提供され、カスタマイズが可能です。
まとめ
この記事では、Windows 11環境でPythonを使ってMeCabを利用する方法について解説しました。形態素解析の重要性や基本的な実施例、さらに利用可能な辞書(IPA辞書、NEologdなど)の特徴について触れました。
以下のポイントを押さえておきましょう。
- MeCabは高速で汎用性が高く、多くのプログラミング言語に対応。
- mecab-python3を使えばPythonから簡単にMeCabを操作可能。
- IPA辞書やNEologdなどの辞書を活用することで解析精度を向上可能。
- Windows環境ではMeCab本体のインストールとUTF-8設定が重要。
形態素解析は自然言語処理の基本ですが、MeCabを適切に設定することで、テキスト解析やデータ分析の効率が大幅に向上します。本記事の内容を参考に、ぜひ実際のプロジェクトで活用してみてください。