当ブログのコンテンツ・情報について、できる限り正確な情報を提供するように努めておりますが、正確性や安全性を保証するものではありません。
当サイトに掲載された内容によって生じた損害等の一切の責任を負いかねますので、予めご了承ください。
Pythonで実践!WEBスクレイピングの基礎と高度なテクニック徹底解説

WEBスクレイピングは、インターネット上の情報を自動的に収集する強力な技術です。
しかし、法的な注意点や技術的な課題も存在します。本記事では、Pythonを使ったWEBスクレイピングの基本から応用までを解説し、初心者でも安心してWEBスクレイピングできることを目的とします。
目次
この記事で使用するPythonライブラリ
この記事では以下のPythonライブラリを使用します。
| ライブラリ | 用途 | ライセンス |
|---|---|---|
| BeautifulSoup | HTMLの解析 | MIT |
| requests | HTTPリクエスト | Apache License 2.0 |
| Selenium | Webブラウザの自動操作 動的コンテンツのスクレイピング | Apache License 2.0 |
| pandas | データ分析やデータ操作 | 修正BSD |
| time | 時間や待機処理の操作 | Python標準モジュール |
BeautifulSoupとは?
HTMLやXML文書を解析・操作するためのライブラリです。DOMツリーを使わずに、簡単なコードでウェブページから必要なデータを抽出できるため、スクレイピングやデータ解析に広く使用されています。
不完全なHTMLやXML文書を補正する機能も備えており、ウェブページの構造が複雑であっても正確にデータを抽出できます。MITライセンスの下で公開されており、商用利用を含む自由な使用、修正、再配布が許可されています。
requestsとは?
HTTPリクエストを簡単に送信するためのライブラリです。URLに対してわずかなコードでリクエストを送信し、応答を取得できます。特にウェブスクレイピングやAPIの利用時に便利で、複雑なHTTP操作をシンプルに行える点が魅力です。Apache License 2.0の下で公開されており、商用利用を含む自由な使用、修正、再配布が許可されています。
Seleniumとは?
Webブラウザを自動操作するためのライブラリおよびツールキットです。ウェブアプリケーションのテストや、動的なコンテンツを含むウェブページからのデータ収集に使用されます。
ブラウザを操作し、指定したページを開き、ユーザーアクションをシミュレートすることで、動的に生成されるコンテンツも取得できます。Apache License 2.0の下で公開されており、商用利用を含む自由な使用、修正、再配布が許可されています。
pandasとは?
データ分析やデータ操作のためのライブラリです。データフレームというデータ構造を用いて、データの読み込み、変換、集計、可視化などを効率的に行うことができます。ExcelやCSV、SQLデータベースなどからデータを簡単に読み込み可能です。修正BSDライセンスのオープンソースであり、商用利用を含む自由な使用、修正、再配布が許可されています。
WEBスクレイピングの注意事項
WEBスクレイピングを行う前に、必ず確認すべきポイントがいくつかあります。まず、スクレイピング対象のサイトが提供する利用規約やrobots.txtファイルを確認しましょう。これらのファイルには、どのページがスクレイピング可能か、どのデータが取得可能かが記載されています。
利用規則を確認する
サイトによっては利用規則でWEBスクレイピング(ロボットアクセス、自動アクセス、自動データ収集等)を禁止または制限している場合があります。例えば、以下のサイトではWEBスクレイピングが禁止または制限されています。
Google 検索
Google 検索のスクレイピング、スクレイピングによるデータの購入
Google Ads API のポリシー
Google 検索結果ページやその他の Google のプロパティをスクレイピングすることはできません。また、スクレイピングされた Google のデータをサードパーティから間接的に入手することも、禁止されています。Google 以外の正当なデータソースから入手した検索データを含むレポートを公開する場合、データソースとデータ収集手法をレポートで開示する必要があります。
Yahoo!検索
Yahoo!検索は、お客様ご自身による検索利用を目的としたサービスです。
リンク、二次利用、著作権について
検索エンジン運営者が行うインデックス作成目的のクロールを除き、クロールやスクレイピングといった機械的に情報収集を行う行為、そうした情報を利用する行為、検索サービス提供の妨害を目的として第三者を利用して大量の検索を行わせる行為、および多大な負荷をかける検索行為などは禁止しております。
不適切と判断したアクセスは、遮断させていただく場合があります。
Amazon
利用許可およびサイトへのアクセス
Amazon.co.jp利用規約
本規約およびサービス規約の遵守を条件とし、アマゾンまたはコンテンツ提供者は、アマゾンサービスを限定的、非独占的、非商業的および個人的に利用する権利をお客様に許諾します(譲渡およびサブライセンス不可)。この利用許可には、アマゾンサービスまたはそのコンテンツの転売および商業目的での利用、製品リスト、解説、価格などの収集と利用、アマゾンサービスまたはそのコンテンツの二次的利用、第三者のために行うアカウント情報のダウンロードとコピーやその他の利用、データマイニング、ロボットなどのデータ収集・抽出ツールの使用は、一切含まれません。
ライブドア
1.4 禁止行為
当社の事前の承諾を得ることなく、自動化された手段(いわゆるスクレイピング。プログラム・自動化ツール・ロボットなどこれらに準ずる手段を含む。)を用いて当社の提供するコンテンツ等を取得する行為、または、アクセス許可のないデータへのアクセスを試みる行為
利用規約
robots.txtファイルを確認する
WEBスクレイピングを始める前に、対象サイトのrobots.txtファイルを確認することが基本です。robots.txtは検索エンジンなどのクローラーに対して、どのページにアクセスしてよいか、どのページにはアクセス禁止かを指示するためのファイルです。たとえば、以下のようなルールが含まれることがあります。
- Disallow:特定のページやディレクトリへのアクセスを禁止する。
- Allow:特定のページやディレクトリへのアクセスを許可する。
robots.txtファイルを無視してWEBスクレイピングを行うと、サイト運営者の意図に反した行為になるので必ず遵守するようにしましょう。
robots.txtの確認方法
STEP
ターゲットサイトのURLの末尾に"/robots.txt"を追加
インターネットブラウザのアドレスバーに、ターゲットサイトのURLの末尾に/robots.txtを追加してアクセスします。
https://news.yahoo.co.jp/robots.txtSTEP
robots.txtファイルの内容を確認
https://news.yahoo.co.jp/robots.txtの内容は下記のとおりです。DisallowやAllowといった指示を注意深く確認し、スクレイピング可能なページと禁止されているページを把握します。
robots.txtの詳細はスクレイピング、クローリングする時の注意点をご参照ください。
https://news.yahoo.co.jp/robots.txtの内容
User-agent: *
Disallow: /search
Allow: /search/about
Allow: /search/static
Allow: /search/howsearchworks
Disallow: /sdch
Disallow: /groups
Disallow: /index.html?
Disallow: /?
Allow: /?hl=
Disallow: /?hl=*&
Allow: /?hl=*&gws_rd=ssl$
Disallow: /?hl=*&*&gws_rd=ssl
Allow: /?gws_rd=ssl$
Allow: /?pt1=true$
Disallow: /imgres
Disallow: /u/
Disallow: /setprefs
Disallow: /default
Disallow: /m?
Disallow: /m/
Allow: /m/finance
Disallow: /wml?
Disallow: /wml/?
Disallow: /wml/search?
Disallow: /xhtml?
Disallow: /xhtml/?
Disallow: /xhtml/search?
Disallow: /xml?
Disallow: /imode?
Disallow: /imode/?
Disallow: /imode/search?
Disallow: /jsky?
Disallow: /jsky/?
Disallow: /jsky/search?
Disallow: /pda?
Disallow: /pda/?
Disallow: /pda/search?
Disallow: /sprint_xhtml
Disallow: /sprint_wml
Disallow: /pqa
Disallow: /gwt/
Disallow: /purchases
Disallow: /local?
Disallow: /local_url
Disallow: /shihui?
Disallow: /shihui/
Disallow: /products?
Disallow: /product_
Disallow: /products_
Disallow: /products;
Disallow: /print
Disallow: /books/
Disallow: /bkshp?*q=*
Disallow: /books?*q=*
Disallow: /books?*output=*
Disallow: /books?*pg=*
Disallow: /books?*jtp=*
Disallow: /books?*jscmd=*
Disallow: /books?*buy=*
Disallow: /books?*zoom=*
Allow: /books?*q=related:*
Allow: /books?*q=editions:*
Allow: /books?*q=subject:*
Allow: /books/about
Allow: /booksrightsholders
Allow: /books?*zoom=1*
Allow: /books?*zoom=5*
Allow: /books/content?*zoom=1*
Allow: /books/content?*zoom=5*
Disallow: /ebooks/
Disallow: /ebooks?*q=*
Disallow: /ebooks?*output=*
Disallow: /ebooks?*pg=*
Disallow: /ebooks?*jscmd=*
Disallow: /ebooks?*buy=*
Disallow: /ebooks?*zoom=*
Allow: /ebooks?*q=related:*
Allow: /ebooks?*q=editions:*
Allow: /ebooks?*q=subject:*
Allow: /ebooks?*zoom=1*
Allow: /ebooks?*zoom=5*
Disallow: /patents?
Disallow: /patents/download/
Disallow: /patents/pdf/
Disallow: /patents/related/
Disallow: /scholar
Disallow: /citations?
Allow: /citations?user=
Disallow: /citations?*cstart=
Allow: /citations?view_op=new_profile
Allow: /citations?view_op=top_venues
Allow: /scholar_share
Disallow: /s?
Disallow: /maps?
Allow: /maps?*output=classic*
Allow: /maps?*file=
Disallow: /mapstt?
Disallow: /mapslt?
Disallow: /mapabcpoi?
Disallow: /maphp?
Disallow: /mapprint?
Disallow: /maps/
Allow: /maps/search/
Allow: /maps/dir/
Allow: /maps/d/
Allow: /maps/reserve
Allow: /maps/about
Allow: /maps/match
Disallow: /maps/api/js/
Allow: /maps/api/js
Disallow: /mld?
Disallow: /staticmap?
Disallow: /help/maps/streetview/partners/welcome/
Disallow: /help/maps/indoormaps/partners/
Disallow: /lochp?
Disallow: /center
Disallow: /ie?
Disallow: /blogsearch/
Disallow: /blogsearch_feeds
Disallow: /advanced_blog_search
Disallow: /uds/
Disallow: /chart?
Disallow: /transit?
Allow: /calendar$
Allow: /calendar/about/
Disallow: /calendar/
Disallow: /cl2/feeds/
Disallow: /cl2/ical/
Disallow: /coop/directory
Disallow: /coop/manage
Disallow: /trends?
Disallow: /trends/music?
Disallow: /trends/hottrends?
Disallow: /trends/viz?
Disallow: /trends/embed.js?
Disallow: /trends/fetchComponent?
Disallow: /trends/beta
Disallow: /trends/topics
Disallow: /trends/explore?
Disallow: /trends/embed
Disallow: /trends/api
Disallow: /musica
Disallow: /musicad
Disallow: /musicas
Disallow: /musicl
Disallow: /musics
Disallow: /musicsearch
Disallow: /musicsp
Disallow: /musiclp
Disallow: /urchin_test/
Disallow: /movies?
Disallow: /wapsearch?
Allow: /safebrowsing/diagnostic
Allow: /safebrowsing/report_badware/
Allow: /safebrowsing/report_error/
Allow: /safebrowsing/report_phish/
Disallow: /reviews/search?
Disallow: /orkut/albums
Disallow: /cbk
Disallow: /recharge/dashboard/car
Disallow: /recharge/dashboard/static/
Disallow: /profiles/me
Allow: /profiles
Disallow: /s2/profiles/me
Allow: /s2/profiles
Allow: /s2/oz
Allow: /s2/photos
Allow: /s2/search/social
Allow: /s2/static
Disallow: /s2
Disallow: /transconsole/portal/
Disallow: /gcc/
Disallow: /aclk
Disallow: /cse?
Disallow: /cse/home
Disallow: /cse/panel
Disallow: /cse/manage
Disallow: /tbproxy/
Disallow: /imesync/
Disallow: /shenghuo/search?
Disallow: /support/forum/search?
Disallow: /reviews/polls/
Disallow: /hosted/images/
Disallow: /ppob/?
Disallow: /ppob?
Disallow: /accounts/ClientLogin
Disallow: /accounts/ClientAuth
Disallow: /accounts/o8
Allow: /accounts/o8/id
Disallow: /topicsearch?q=
Disallow: /xfx7/
Disallow: /squared/api
Disallow: /squared/search
Disallow: /squared/table
Disallow: /qnasearch?
Disallow: /app/updates
Disallow: /sidewiki/entry/
Disallow: /quality_form?
Disallow: /labs/popgadget/search
Disallow: /buzz/post
Disallow: /compressiontest/
Disallow: /analytics/feeds/
Disallow: /analytics/partners/comments/
Disallow: /analytics/portal/
Disallow: /analytics/uploads/
Allow: /alerts/manage
Allow: /alerts/remove
Disallow: /alerts/
Allow: /alerts/$
Disallow: /ads/search?
Disallow: /ads/plan/action_plan?
Disallow: /ads/plan/api/
Disallow: /ads/hotels/partners
Disallow: /phone/compare/?
Disallow: /travel/clk
Disallow: /travel/entity
Disallow: /travel/search
Disallow: /travel/flights/s/
Disallow: /travel/hotels/entity
Disallow: /travel/hotels/stories
Disallow: /hotelfinder/rpc
Disallow: /hotels/rpc
Disallow: /commercesearch/services/
Disallow: /evaluation/
Disallow: /chrome/browser/mobile/tour
Disallow: /compare/*/apply*
Disallow: /forms/perks/
Disallow: /shopping/suppliers/search
Disallow: /ct/
Disallow: /edu/cs4hs/
Disallow: /trustedstores/s/
Disallow: /trustedstores/tm2
Disallow: /trustedstores/verify
Disallow: /adwords/proposal
Disallow: /shopping?*
Disallow: /shopping/product/
Disallow: /shopping/seller
Disallow: /shopping/ratings/account/metrics
Disallow: /shopping/ratings/merchant/immersivedetails
Disallow: /shopping/reviewer
Disallow: /storefront
Disallow: /storepicker
Allow: /about/careers/applications/
Allow: /about/careers/applications-a/
Allow: /about/careers/applications/teams/
Allow: /about/careers/applications-a/teams/
Allow: /about/careers/applications/locations/
Allow: /about/careers/applications-a/locations/
Allow: /about/careers/applications/benefits/
Allow: /about/careers/applications-a/benefits/
Allow: /about/careers/applications/students/
Allow: /about/careers/applications-a/students/
Allow: /about/careers/applications/jobs/results/$
Allow: /about/careers/applications-a/jobs/results/$
Allow: /about/careers/applications/cloud/
Allow: /about/careers/applications-a/cloud/
Allow: /about/careers/applications/hardware/
Allow: /about/careers/applications-a/hardware/
Allow: /about/careers/applications/eeo/
Allow: /about/careers/applications-a/eeo/
Allow: /about/careers/applications/how-we-hire/
Allow: /about/careers/applications-a/how-we-hire/
Allow: /about/careers/applications/interview-tips/
Allow: /about/careers/applications-a/interview-tips/
Disallow: /about/careers/applications/
Disallow: /about/careers/applications-a/
Disallow: /about/careers/applications/jobs/results?page=
Disallow: /about/careers/applications/jobs/results/?page=
Disallow: /about/careers/applications/jobs/results?*&page=
Disallow: /about/careers/applications/jobs/results/?*&page=
Disallow: /landing/signout.html
Disallow: /webmasters/sitemaps/ping?
Disallow: /ping?
Disallow: /gallery/
Disallow: /landing/now/ontap/
Allow: /searchhistory/
Allow: /maps/reserve
Allow: /maps/reserve/partners
Disallow: /maps/reserve/api/
Disallow: /maps/reserve/search
Disallow: /maps/reserve/bookings
Disallow: /maps/reserve/settings
Disallow: /maps/reserve/manage
Disallow: /maps/reserve/payment
Disallow: /maps/reserve/receipt
Disallow: /maps/reserve/sellersignup
Disallow: /maps/reserve/payments
Disallow: /maps/reserve/feedback
Disallow: /maps/reserve/terms
Disallow: /maps/reserve/m/
Disallow: /maps/reserve/b/
Disallow: /maps/reserve/partner-dashboard
Disallow: /about/views/
Disallow: /intl/*/about/views/
Disallow: /local/cars
Disallow: /local/cars/
Disallow: /local/dealership/
Disallow: /local/dining/
Disallow: /local/place/products/
Disallow: /local/place/reviews/
Disallow: /local/place/rap/
Disallow: /local/tab/
Disallow: /localservices/*
Allow: /finance
Allow: /js/
Disallow: /nonprofits/account/
Disallow: /uviewer
Disallow: /landing/cmsnext-root/
# AdsBot
User-agent: AdsBot-Google
Disallow: /maps/api/js/
Allow: /maps/api/js
Disallow: /maps/api/place/js/
Disallow: /maps/api/staticmap
Disallow: /maps/api/streetview
# Crawlers of certain social media sites are allowed to access page markup when google.com/imgres* links are shared. To learn more, please contact images-robots-allowlist@google.com.
User-agent: Twitterbot
Allow: /imgres
Allow: /search
Disallow: /groups
Disallow: /hosted/images/
Disallow: /m/
User-agent: facebookexternalhit
Allow: /imgres
Allow: /search
Disallow: /groups
Disallow: /hosted/images/
Disallow: /m/
Sitemap: https://www.google.com/sitemap.xmlUser-agent: **はワイルドカードで全てのクローラーを指します。Disallow: /search:/search以下のページにはアクセスしないように指示しています。(例外あり)- 例外的に
Allow: /search/aboutなどのフォルダやページにはアクセスを許可しています。
- 例外的に
User-agent: AdsBot-GoogleAdsBot-Googleという特定のクローラーに対する指示で、Googleの広告クローラーが特定のAPIやページにアクセスしないように制限しています。
User-agent: Twitterbotおよびfacebookexternalhit- TwitterやFacebookのクローラーに対する指示で、特定のページや画像へのアクセスを許可または禁止しています。
Sitemap: https://www.google.com/sitemap.xml- Googleのサイトマップファイルの場所を指定しており、クローラーに対して効率的なクロールをサポートしています。
サーバー負荷を考慮する
WEBスクレイピングを行う際に、スクレイピング対象のサーバーに過度な負荷をかけないようにすることが重要です。
短時間で大量のリクエストを送るとサーバーが過負荷状態になり、サービス停止やアクセス制限の原因になることがあります。さらに、スクレイピング対象のサーバーをダウンさせた場合、偽計業務妨害罪等の刑事事件に発展するおそれもあります。
これを避けるために、以下のポイントに注意しましょう。
- リクエストの間に十分な間隔を設ける(例:1秒以上のディレイを入れる)。
- ページ要素の全てを読み込んでから、次の処理を実行する。
- スクレイピング対象のサイトが規定しているデータアクセス量の制限を守る。
- 不要なリクエストを避けるために、スクレイピング対象を絞り込む。
- ターゲットサイトが提供しているAPIがあれば、APIの利用も検討する。
著作権等に注意する
WEBスクレイピングで取得したデータは、法的に保護されたコンテンツである可能性があります。そのため、著作権法やその他の法令に違反しないよう、取得したデータの利用方法に注意が必要です。具体的には、以下の点に注意してください。
- スクレイピングしたデータをそのまま公開しない。
- スクレイピングしたデータを商用利用する場合は、必ずライセンスや許可を確認する。
- 著作権法やその他の法令に違反しないよう、データの使用に関して十分な配慮を行う。
ただし、著作権やその他の法令への遵守は手動取得、自動取得(スクレイピング)問わず考慮すべきですので、誤解しないようお願いいたします。
静的コンテンツのWEBスクレイピング手法
Pythonには、WEBスクレイピングに利用できる便利なライブラリが多くあります。代表的なライブラリとして、BeautifulSoupとrequestsがあります。これらを使って、基本的なWEBスクレイピングを行ってみましょう。
必要なライブラリのインストール
必要なライブラリをインストールします。PowerShellで以下のコマンドを実行して、BeautifulSoupとrequestsライブラリをインストールしてください。
pip install beautifulsoup4 requestsWEBスクレイピングの基本
このコードでは指定したURLのページからタイトルを取得します。requestsライブラリでページを取得し、BeautifulSoupでHTMLを解析するという基本的な流れです。
import requests
from bs4 import BeautifulSoup
# URLを指定
url = 'https://kodoloom.com/web-scraping-in-python/'
# ページを取得
response = requests.get(url)
# ページの内容を解析
soup = BeautifulSoup(response.text, 'html.parser')
# 特定の要素を抽出
title = soup.find('title').text
print(f'ページのタイトル: {title}')特定の要素のクラスやIDを指定してコンテンツを取得
WEBページ内の特定の要素をスクレイピングする場合、クラス名やIDを指定して要素を取得するのが一般的です。以下に、クラスやIDを指定してコンテンツを取得する方法を紹介します。
テキストコンテンツの取得
特定のクラス名を持つテキストコンテンツを取得するためには、find()やfind_all()メソッドを使用します。ここでは、クラス名 class-text とID id-text を持つ要素を取得する例を示します。
このコードでは、指定したURLからクラス名class-textを持つ要素と、IDid-textを持つ要素を取得しています。
サンプルテキスト1
サンプルテキスト2
import requests
from bs4 import BeautifulSoup
# URLを指定
url = 'https://kodoloom.com/web-scraping-in-python/'
# ページを取得
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# クラス名'class-text'を持つ要素を取得
class_text = soup.find('p', class_='class-text').text
print(f'クラス名で取得したテキスト: {class_text}') # 出力結果: クラス名で取得したテキスト: サンプルテキスト1
# ID'id-text'を持つ要素を取得
id_text = soup.find('p', id='id-text').text
print(f'IDで取得したテキスト: {id_text}') # 出力結果: IDで取得したテキスト: サンプルテキスト2リンクをクリック
リンクをクリックして別のページに移動する場合も、リンクのhref属性を取得することで対応できます。
import requests
from bs4 import BeautifulSoup
# URLを指定
url = 'https://kodoloom.com/web-scraping-in-python/'
# ページを取得
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# class名'link-content'の<p>内の<a>タグを探しリンクを取得
link_tag = soup.find('p', class_='link-content').find('a')
# 取得したリンクのURL
link_url = link_tag.get('href')
print(f'取得したリンク先: {link_url}') # 例: https://kodoloom.com/
# 取得したリンク先に移動し、タイトルを取得
link_response = requests.get(link_url)
link_soup = BeautifulSoup(link_response.text, 'html.parser')
link_title = link_soup.find('title').text
print(f'リンク先のページのタイトル: {link_title}') # 例: Kode・Loom | 未来を紡ぐ、あなたのコードで。リストデータの取得
次に、WEBページ内のリストデータをスクレイピングする方法を紹介します。クラス名list-contentsを持つリストアイテムを取得し、その内容を出力する例です。
BeautifulSoupの find メソッドでは、クラス名が複数ある場合に正確に完全一致する必要があります。クラスを部分一致で検索すにはclass_ パラメータではなくattrsパラメータを使用します。
このコードでは指定されたURLからリストデータを取得し、for文を使用して各行のデータを順番に処理しています。
あわせて読みたい

【Pythonのfor文徹底解説】初心者~中級者向け
Pythonのfor文は非常に強力なツールで、初心者がプログラミングを学び始める際に必ず習得すべきものです。 この記事では、Pythonのfor文を使ってどのようなことができる...
- サンプルリスト1
- サンプルリスト2
- サンプルリスト3
import requests
from bs4 import BeautifulSoup
import time
# URLを指定
url = 'https://kodoloom.com/web-scraping-in-python/'
# ページを取得
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# class名'list-contents'の<ul>タグを探し、リストデータの取得
list_items = soup.find('ul', attrs={'class': 'list-contents'}).find_all('li')
# 各リストアイテムを1秒ごとに取得
for item in list_items:
print(f'リストアイテム: {item.text}')
# 出力結果:
# リストアイテム: サンプルリスト1
# リストアイテム: サンプルリスト2
# リストアイテム: サンプルリスト3表データの取得
次に、ページ内の表データを取得してみましょう。以下のコードは、指定したURLから表のデータを取得し各行を処理する方法です。
| 番号 | 名前 | 年齢 |
|---|---|---|
| 1 | 田中 | 25 |
| 2 | 佐藤 | 30 |
| 3 | 鈴木 | 28 |
import requests
from bs4 import BeautifulSoup
import time
# URLを指定
url = 'https://kodoloom.com/web-scraping-in-python/'
# ページを取得
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# <figure id="sample-table"> 配下の <table> タグの表データを取得
figure = soup.find('figure', id='sample-table')
table = figure.find('table')
rows = table.find_all('tr')
# 各行のデータを取得
for row in rows[0:]:
columns = row.find_all('td')
row_data = [column.text for column in columns]
print(f'行データ: {row_data}')
# 出力結果:
# 行データ: ['1', '田中', '25']
# 行データ: ['2', '佐藤', '30']
# 行データ: ['3', '鈴木', '28']動的コンテンツのWEBスクレイピング手法
より高度なWEBスクレイピングには、JavaScript等で生成された動的なコンテンツに対応する方法が必要です。ここでは、Seleniumを使った動的ページのスクレイピングを紹介します。Seleniumはインターネットブラウザを自動操作して動的なコンテンツを取得するためのライブラリです。
Seleniumのセットアップ
SeleniumでWEBスクレイピングを行うためには、いくつかのセットアップ手順が必要です。以下に詳細な手順を説明します。
STEP
Seleniumのインストール
Seleniumをインストールします。PowerShellで以下のコマンドを実行して、Seleniumライブラリをインストールしてください。
pip install seleniumSTEP
WebDriverのダウンロード
Seleniumはブラウザを自動操作するために「WebDriver」というソフトウェアを使用します。以下は代表的なブラウザとそのWebDriverです。本記事ではChromeで解説します。
- Google Chrome: ChromeDriver
- Mozilla Firefox: GeckoDriver
- Microsoft Edge: EdgeDriver
StableバージョンのChromeDriverをダウンロードします。Windows11の場合、chromedriver win64の右のURLをコピーしてアドレスバーに入力し、Enterキーを押すとダウンロードが開始します。
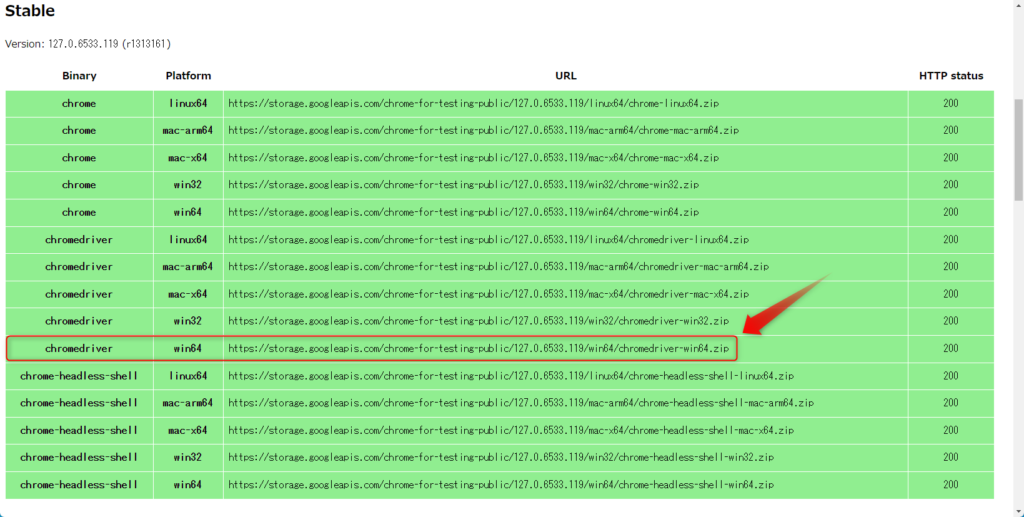
念の為、ChromeのバージョンとChromeDriverのバージョンが一致していることを確認してください。Chromeが最新の状態でない場合、バージョンが一致しないことがあります。
Chromeのバージョン確認法
STEP
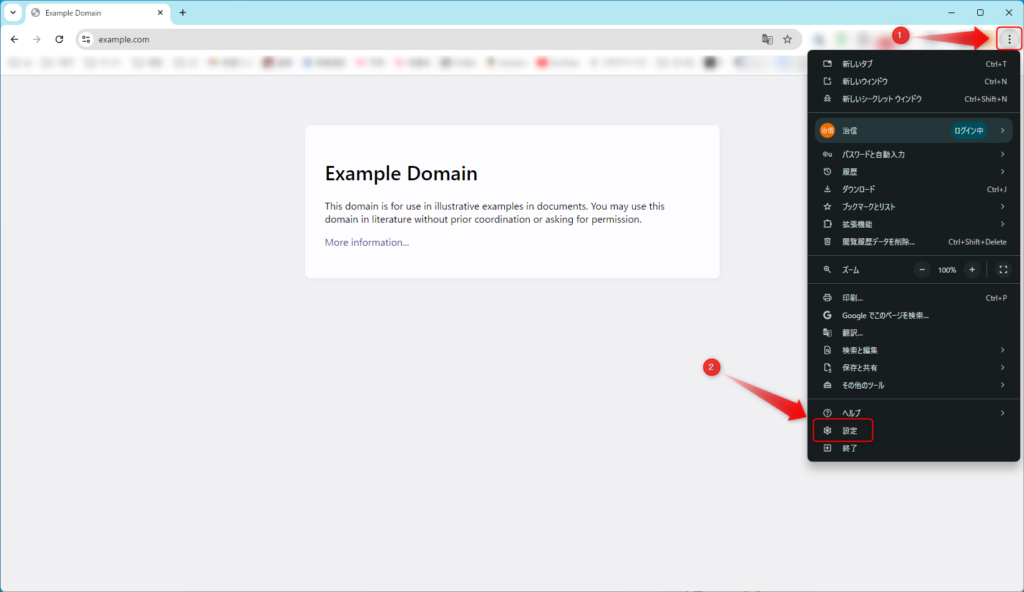
Chromeの設定を開く
Chromeの右上の「︙」マークをクリックし、「設定」をクリックします。
STEP
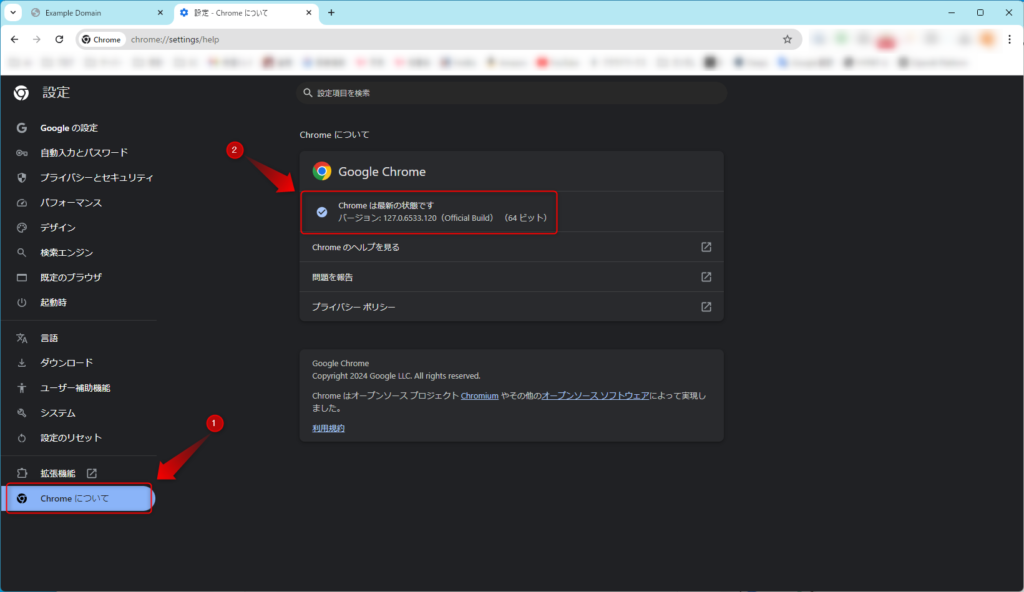
Chromの状態の確認
Chromeが最新であることと、バージョンを確認してください
STEP
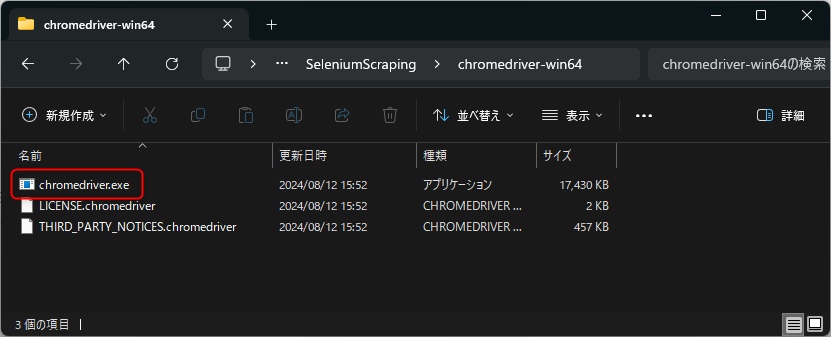
WebDriverの保存
WebDriverをダウンロード後、展開し任意の場所に保存します。ここではC:\py\SeleniumScraping\chromedriver-win64に保存しています。
Seleniumを使ったスクレイピング
スクロールで追加されるコンテンツ
Seleniumを使用して、スクロールによって追加されるコンテンツを取得する方法を説明します。この場合、コンテンツが自動的にロードされるため、スクロール動作を再現しながらデータを収集します。
このコードでは、ページをスクロールして動的にロードされるアイテムを取得します。スクロール動作を再現しながら、各アイテムを取得しています。
アイテム1
アイテム2
アイテム3
アイテム4
アイテム5
アイテム6
アイテム7
アイテム8
アイテム9
アイテム10
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import time
# WebDriverのパスを指定してサービスを作成
service = Service('C:\\py\\SeleniumScraping\\chromedriver-win64\\chromedriver.exe')
driver = webdriver.Chrome(service=service)
# URLにアクセス
driver.get('https://kodoloom.com/web-scraping-in-python/')
# IDが'dynamic-content'の要素をページから取得し、スクロールして動的にロードされるコンテンツを取得
dynamic_content = driver.find_element(By.ID, 'dynamic-content')
# JavaScriptを使ってスクロールする
for _ in range(20): # スクロールを20回繰り返す
driver.execute_script("arguments[0].scrollTop = arguments[0].scrollHeight", dynamic_content)
time.sleep(1)
# アイテムを取得
items = dynamic_content.find_elements(By.CLASS_NAME, 'item')
for item in items:
print(f'取得したアイテム: {item.text}')
# WebDriverを終了
driver.quit()
"""
出力結果例:
取得したアイテム: アイテム1
取得したアイテム: アイテム2
取得したアイテム: アイテム3
取得したアイテム: アイテム4
取得したアイテム: アイテム5
取得したアイテム: アイテム6
取得したアイテム: アイテム7
取得したアイテム: アイテム8
取得したアイテム: アイテム9
取得したアイテム: アイテム10
取得したアイテム: アイテム11
取得したアイテム: アイテム12
取得したアイテム: アイテム13
取得したアイテム: アイテム14
取得したアイテム: アイテム15
︙
取得したアイテム: アイテム100
"""クリックイベントで表示される情報
ボタンをクリックして表示される情報を取得する方法を示します。Seleniumを使ってボタンをクリックし、表示されたテキストを取得します。
このコードでは、指定されたボタンをクリックして表示される隠れた情報を取得しています。情報が表示されるまでのディレイは、必要に応じて time.sleep() を使用します。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import time
# WebDriverのパスを指定してサービスを作成
service = Service('C:\\py\\SeleniumScraping\\chromedriver-win64\\chromedriver.exe')
driver = webdriver.Chrome(service=service)
# URLにアクセス
driver.get('https://kodoloom.com/web-scraping-in-python/')
# IDが'info-button'のボタンをクリックして情報を表示
info_button = driver.find_element(By.ID, 'info-button')
info_button.click()
# 1秒待機して、情報が表示されるのを待つ
time.sleep(1)
# IDが'hidden-info'要素を探し、表示された情報を取得
hidden_info = driver.find_element(By.ID, 'hidden-info')
print(f'表示された情報: {hidden_info.text}') # 出力結果: 表示された情報: これはクリックで表示される隠された情報です。
# WebDriverを終了
driver.quit()クリックイベントでリンク先に移動
Seleniumを使ってリンク先に移動する際には、ボタンをクリックしてリンク先へ移動します。移動先のページのタイトルを取得する例を示します。
このコードでは、リンク先に移動してから新しいページのタイトルを取得しています。ページのロードが完了するまで待機するために、time.sleep()を使用しています。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import time
# WebDriverのパスを指定してサービスを作成
service = Service('C:\\py\\SeleniumScraping\\chromedriver-win64\\chromedriver.exe')
driver = webdriver.Chrome(service=service)
# URLにアクセス
driver.get('https://kodoloom.com/web-scraping-in-python/')
# IDが'navigate-button'のボタンを探しクリック
navigate_button = driver.find_element(By.ID, 'navigate-button')
navigate_button.click()
# 新しいページのタイトルを取得する前にページがロードされるまで待機
time.sleep(2)
# 新しいページのタイトルを取得
new_title = driver.title
print(f'新しいページのタイトル: {new_title}') # 出力結果: 新しいページのタイトル: Kode・Loom | 未来を紡ぐ、あなたのコードで。
# WebDriverを終了
driver.quit()テキストボックスに入力してボタンをクリック
テキストボックスに値を入力し、ボタンをクリックして結果を取得する方法を示します。この例では、正しいパスワードを入力して結果を表示します。
このコードでは、テキストボックスに「password」と入力し、ボタンをクリックして結果メッセージを取得します。パスワードが正しい場合は「正しいパスワードです」というメッセージが表示されます。なお、ここではpasswordをハードコート(コードに直接記述すること)していますが、実際にパスワードを扱う場合は環境変数にパスを通すなどセキュリティ対策をしてください。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import time
# WebDriverのパスを指定してサービスを作成
service = Service('C:\\py\\SeleniumScraping\\chromedriver-win64\\chromedriver.exe')
driver = webdriver.Chrome(service=service)
# URLにアクセス
driver.get('https://kodoloom.com/web-scraping-in-python/')
# IDが'passwordInput'の要素(テキストボックス)を探し、パスワードを入力して、IDが'checkButton'のボタンをクリック
password_input = driver.find_element(By.ID, 'passwordInput')
password_input.send_keys('password') # 正しいパスワードを入力
check_button = driver.find_element(By.ID, 'checkButton')
check_button.click()
# 結果を取得する前に、メッセージが表示されるまで待機
time.sleep(1)
# IDが'checkButton'の要素を取得し結果を出力
result_message = driver.find_element(By.ID, 'resultMessage')
print(f'結果メッセージ: {result_message.text}') # 出力結果: 結果メッセージ: 正しいパスワードです
# WebDriverを終了
driver.quit()別タブや別ウィンドウの要素を補足する
WEBスクレイピングをしていると強制的に別タブや別ウィンドウが開く場合があります。Seleniumでのスクレイピングでは別タブや別ウィンドウを正確に捕捉する必要があります。
Seleniumではwindow_handles を使用することで、開かれたすべてのタブやウィンドウの情報を取得し、切り替えながら操作を行うことが可能です。window_handles は現在開いているタブやウィンドウのリストを提供してくれるので、リスト内のインデックスを指定して操作することで、目的のタブに切り替えることができます。
例えば、特定のリンクをクリックして別タブが開いた場合は、以下のように操作できます。
window_handlesで新しいタブのハンドルを取得する。switch_to.window()を使って新しいタブに切り替える。- 必要な情報を取得、または操作を行った後に、再び元のタブに戻す。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import time
# WebDriverのパスを指定してサービスを作成
service = Service('C:\\py\\SeleniumScraping\\chromedriver-win64\\chromedriver.exe')
driver = webdriver.Chrome(service=service)
# URLにアクセス
driver.get('https://kodoloom.com/web-scraping-in-python/')
# 現在のページのタイトルを取得
original_title = driver.title
print(f'現在のページのタイトル: {original_title}') # 出力結果: 現在のページのタイトル: Pythonで実践!WEBスクレイピングの基礎と高度なテクニック徹底解説 | Kode・Loom
# class名'link-open-new-tab'の<p>内の<a>タグを探しリンクを取得しクリック
link = driver.find_element(By.CSS_SELECTOR, "p.link-open-new-tab a")
link.click()
# 別タブが開くので、タブを切り替える
driver.switch_to.window(driver.window_handles[1])
# 新しいページのタイトルを取得する前にページがロードされるまで待機
time.sleep(2)
# 新しいページのタイトルを取得
new_title = driver.title
print(f'新しいページのタイトル: {new_title}') # 出力結果: 新しいページのタイトル: Kode・Loom | 未来を紡ぐ、あなたのコードで。
# 新しいページを閉じ、元のページに戻る
driver.close()
driver.switch_to.window(driver.window_handles[0])
# 元のページのタイトルを取得して確認
original_title_after = driver.title
print(f'元のページのタイトルに戻りました: {original_title_after}') # 出力結果: 元のページのタイトルに戻りました: Pythonで実践!WEBスクレイピングの基礎と高度なテクニック徹底解説 | Kode・Loom
# WebDriverを終了
driver.quit()インラインフレーム内の要素を補足する
サイトによってはインラインフレーム(iframe要素)が使われていることがあります。インラインフレーム内の要素をスクレイピングするためには、別タブや別ウィンドウと同様に、インラインフレーム内の要素を正確に補足する必要があります。
Seleniumでは、switch_to.frame() メソッドを使ってiframeにフォーカスを移すことができます。また、元のコンテンツに戻るためには、switch_to.default_content() を使用します。
補足する要素
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import time
# WebDriverのパスを指定してサービスを作成
service = Service('C:\\py\\SeleniumScraping\\chromedriver-win64\\chromedriver.exe')
driver = webdriver.Chrome(service=service)
# URLにアクセス
driver.get('https://kodoloom.com/web-scraping-in-python/')
# クラス名'supplemental-element'を持つ要素を取得
element = driver.find_element(By.CLASS_NAME, 'supplemental-element')
print(f"元のフレームの要素テキスト: {element.text}") # 出力結果: 元のフレームの要素テキスト: 補足する要素
# ID名'iframe'のインラインフレーム内のクラス名'supplemental-element'を持つ要素を取得
# iframeに切り替える
iframe = driver.find_element(By.ID, 'iframe')
driver.switch_to.frame(iframe)
# iframe内のクラス名'supplemental-element'を持つ要素を取得
iframe_element = driver.find_element(By.CLASS_NAME, 'supplemental-element')
print(f"iframe内の要素テキスト: {iframe_element.text}") # 出力結果: iframe内の要素テキスト: 補足する要素
# 元のフレームに戻る
driver.switch_to.default_content()
# 再び元のページのクラス名'supplemental-element'を持つ要素を取得
element_after = driver.find_element(By.CLASS_NAME, 'supplemental-element')
print(f"元のフレームに戻った後の要素テキスト: {element_after.text}") # 出力結果: 元のフレームに戻った後の要素テキスト: 補足する要素
# WebDriverを終了
driver.quit()
データの保存と管理
WEBスクレイピングでばデータを構造化して保存する方法が求められます。
スクレイピングで取得したデータを効率的に管理するために、データベースやCSVファイルに保存することが重要です。以下の例では、Pythonのpandasライブラリを使ってデータをCSVファイルに保存する方法を紹介します。
pandasのインストール
pandasをインストールします。PowerShellで以下のコマンドを実行して、BeautifulSoupとrequestsライブラリをインストールしてください。
pip install pandaspandasを使ったCSVファイル保存
以下のコードではこの記事のコンテンツを取得したあと、pandasを使ってCSVファイルに保存しています。
import requests
from bs4 import BeautifulSoup
import pandas as pd
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# 取得したデータを格納する辞書
data = {
"Class Text": [],
"ID Text": [],
"List Items": [],
"Table Rows": [],
"Dynamic Items": [],
"Hidden Info": []
}
# 1. BeautifulSoupを使った静的コンテンツのスクレイピング
# URLを指定
url = 'https://kodoloom.com/web-scraping-in-python/'
# ページを取得
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# クラス名'class-text'を持つ要素を取得
data["Class Text"].append(soup.find('p', class_='class-text').text)
# ID'id-text'を持つ要素を取得
data["ID Text"].append(soup.find('p', id='id-text').text)
# class名'list-contents'の<ul>タグを探し、リストデータの取得
list_items = soup.find('ul', class_='list-contents').find_all('li')
# 各リストアイテムを追加
for item in list_items:
data["List Items"].append(item.text)
# <figure id="sample-table"> 配下の <table> タグの表データを取得
figure = soup.find('figure', id='sample-table')
table = figure.find('table')
rows = table.find_all('tr')
# 各行のデータを追加
for row in rows[1:]: # ヘッダー行を除く
columns = row.find_all('td')
row_data = " | ".join([column.text for column in columns])
data["Table Rows"].append(row_data)
# 2. Seleniumを使った動的コンテンツのスクレイピング
# WebDriverのパスを指定してサービスを作成
service = Service('C:\\py\\SeleniumScraping\\chromedriver-win64\\chromedriver.exe')
driver = webdriver.Chrome(service=service)
# URLにアクセス
driver.get(url)
# IDが'dynamic-content'の要素をページから取得し、スクロールして動的にロードされるコンテンツを取得
dynamic_content = driver.find_element(By.ID, 'dynamic-content')
# JavaScriptを使ってスクロールする
for _ in range(20): # スクロールを20回繰り返す
driver.execute_script("arguments[0].scrollTop = arguments[0].scrollHeight", dynamic_content)
time.sleep(1)
# アイテムを追加
items = dynamic_content.find_elements(By.CLASS_NAME, 'item')
for item in items:
data["Dynamic Items"].append(item.text)
# IDが'info-button'のボタンをクリックして情報を表示
info_button = driver.find_element(By.ID, 'info-button')
info_button.click()
# 1秒待機して、情報が表示されるのを待つ
time.sleep(1)
# IDが'hidden-info'要素を探し、表示された情報を追加
data["Hidden Info"].append(driver.find_element(By.ID, 'hidden-info').text)
# WebDriverを終了
driver.quit()
# 3. pandasを使ってCSVファイルに保存
# データの各リストの長さを揃える
max_length = max(len(data[key]) for key in data)
for key in data:
data[key].extend([""] * (max_length - len(data[key])))
# DataFrameを作成してCSVファイルに保存
df = pd.DataFrame(data)
df.to_csv('scraped_data.csv', index=False, encoding='utf-8-sig')
print("データが 'scraped_data.csv' に保存されました。")このように、スクレイピングしたデータをCSVファイルに保存することで、後から分析や再利用が容易になります。また、SQLiteやMySQLなどのデータベースに保存することで、大量のデータを効率的に管理することも可能です。
まとめ
PythonでWEBスクレイピングを行う際には、法的な注意点を押さえた上で、基本的な手法から応用までを習得することが大切です。
初心者の方は、まずはBeautifulSoupとRequestsを使ったシンプルなスクレイピングから始め、次第にSeleniumを用いた動的コンテンツの取得やデータの保存と管理を学んでいくと良いでしょう。これらの技術を習得することで、インターネット上の情報を効率的に収集し、活用できるようになります。